|
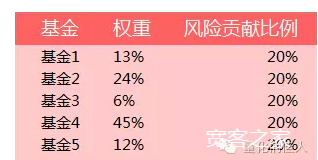
新古典经济学派增长理论告诉我们,全要素生产率的增加能提高劳动和资本的效率,改变经济发展模式。各行各业都享受到了科技进步的红利,这在我们已经有点过度繁荣的金融业,当然也是显而易见的:投资标的、工具越来越多样化,交易软件、交易方式越来越便捷,这些都拉近了人们与金融市场的距离。在科技与金融互撞出火花的Fintech热潮中,“智能资管”、“大数据金融”、“机器学习”等词汇可谓抬头不见低头见。十年前,你去问基金经理什么是“量化投资”、“算法交易”,十有八九不能说清;但在今天的投资领域,你不搞个量化FOF,似乎都不好意思做金融了。 然而,并不是所有宣称“量化”的都是值得信任的。国内量化投资快速发展也为伪科学的滋生**了土壤。普通投资者往往被那些听上去高大上的新名词所迷惑。今天,我们就来看看量化投资界那些隐藏在高深词汇背后可能存在的不科学之处。 基于基金净值的风格评价 在FOF盛行的时代,基金业绩归因尤为重要。一个基金的**益如何分解?有多少**益是风格贡献的?又有多少来自于基金经理自身投资技巧?基金风格是成长型还是价值型?这些都是投资者关注的问题。 对基金的风格进行评价的方法有两种:基于**益(Return-Based)和基于持仓(Holding-Based)。如果采用基于持仓的方法,那么在任何时点,风格都容易被直接观察到。但基于**益的方法就需要我们将一系列风格指数作为自变量,将基金**益作为因变量,做时间序列的多元线性回归。 有些机构推出的基金风格评价体系正是基于**益的(利用基金净值)。但是,这个方法的要求是很严格的。首先,风格因子指数必须互斥:最简单的例子就是将风格指数分为大盘股指数和小盘股指数。其次,风格因子指数是完备的,像“大盘成长”、“小盘价值”这样的分法就是不完备的。第三,风格因子指数必须分别代表独立的风险来源,这也就意味着不能有多重共线性。第四,基金净值数据必须准确和完整。 如今最流行的风格因子就是Barra的风格因子:市场Beta、价值因子、红利因子、成长因子、财务杠杆因子、流动性因子、动量因子、规模因子、波动因子。如果用这套风格因子对私募基金的业绩进行归因与评价,那么,上述四点是值得引起注意的。 模型的长短期错配 每个理论都有其适用范围,原因是在此范围外未获实证支持。例如,绝对购买力平价理论在长期成立,短期就不一定成立。任何金融模型都不可能在所有市场、所有期限适用。如果生搬硬套,得出的结论就缺乏意义了。 现在许多机构在做资产配置时,喜欢用Black-Litterman模型。这个模型对用于大类资产配置还是子类资产配置(行业、个股等)并没有限制,也没对长期配置和短期配置做出要求。但如果你用长时间跨度的资产**益率和短期观点矩阵作为输入变量,就出现了长短期错配的问题:用长期资产**益率协方差矩阵描述短期关系,模型输出的资产配置权重也就没有参考性了。(果仁网上小市值策略的长短期限结构,亲,你考虑过吗?) 基金策略指数泛滥 近几年,随着投资标的的增加,私募基金产品的策略类别越来越丰富:多头、对冲、套利……针对这些策略类型,有些机构根据自身搜集到的私募基金净值信息,编制出了多种策略指数。 然而,这些策略指数的编制过程可能极为粗糙,导致指数本身无法“胜任”业绩基准的内在要求。首先,生存者偏差(Survivorship Bias)严重。正所谓“死人不会说话”,只有存续中的基金才会被纳入指数,而那些已清盘的基金则被剔除在外。指数中的基金都是“幸存者”,这就使得策略指数的业绩总好于实际情况。其次,私募基金净值公布的随意性导致净值数据本身可能存在不准确、不完整的问题。尤其当私募净值公布频率太低的时候,策略指数的波动率会比真实情况低。第四,编制策略指数所选用的私募基金产品样本未必具有好的代表性。第五,对策略的分类没有做到完备和互斥(果仁的做自定义指数的,考虑一下这个)。 将纯资产配置模型用于基金配置 所谓纯资产,就是股票、债券、大宗商品、房地产等具有单种属性的资产。无论是经典的马可维茨均值-方差模型(MVO)还是时下最为流行的风险平价模型(Risk Parity Model),都是针对纯资产进行配置的模型。 而目前涌现出一批“FOF配置工具”,将这些模型用于确定FOF组合中各基金的权重,甚至用在策略配置上(以基金策略指数为标的),这样的结果往往看似实现最优配置,却暗藏风险。因为无论是基金还是基金策略指数,都不是纯资产,而是由多种纯资产组合而成的混合资产。即使股票型基金,也可能有一部分债券持仓;更别提将股票型基金和债券型基金放在一起,试图通过MVO和RP得到最优配置组合了。 举个简单的例子:假定根据风险平价模型确定了5只基金的权重,使这5只基金的风险贡献比例相等。
这5只基金都是混合型基金,持仓资产包括股票和债券。我们将5只基金拆分后按照纯资产(权益类、固**类)重新组合,发现风险并不平价:
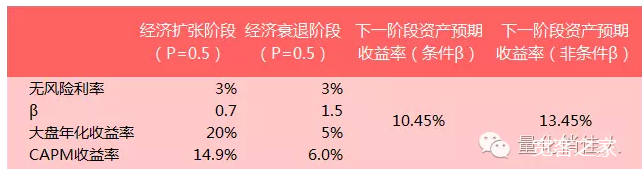
由上表可知,权益类的风险贡献比例为93.2%,固**类的风险贡献比例为6.8%,反而与我们运用风险平价模型配置资产的初衷相违背——结果是某一类资产的风险集中度过高。 (这一点对果仁网上使用复合因子的策略需要小心,复合因子的共线性非常难去除,可以关注长江金工的纯因子构造系列,美女的研报哦) 被操纵的量化策略回测业绩 谁不希望自己的策略有漂亮的业绩?但是,有些人偏偏不诚实,爱自作聪明。 就如同过早地记录**入和将营运成本资本化等财务骗术一样,策略回测业绩也是可以被操纵的。为了使一个策略的回测表现令人满意,研究员往往会不断调优样本内参数,直至样本外数据回测结果达到心中的标准。这就是数据挖掘偏差(Data-mining Bias)。一个策略总能被“优化”得近乎完美,这就出现了过度拟合现象(Overfitting)。 如果研究员不在参数上做文章,而是特意选择一段策略业绩表现好的时间段,剔除业绩相对较差的时间段,则是利用特定时间段偏差(Time-period Bias)来“美化”自己的策略。 类似的小tricks还有很多,但你如果不想在实盘的时候见光死,最好还是摆正心态,脚踏实地做研究。 (关于这一点,亲们,如果你没有在策略上过度拟合优化,来,我给你一个拥抱,男的让开。。。。) 无视情景的模型 我们在利用模型进行预测的时候,应当考虑每个参数的背景——尤其是和经济周期密切相关的变量。 以CAPM为例:假设经济扩张阶段大盘的年化**益率是20%,经济衰退阶段大盘的年化**益率是5%。无风险利率为3%。假定我们已计算出某资产在经济扩张阶段的Beta是0.7,在经济衰退阶段的Beta是1.5,则可算出正确定价的资产**益率在经济扩张阶段为3%+0.7(20%-3%)=14.9%,在经济衰退阶段为3%+1.5(5%-3%)=6%。 假设我们估计下一阶段经济扩张和经济衰退的概率各为0.5,则该资产在下一阶段的**益率为14.9%×0.5+6%×0.5=10.45%。
如果无视经济周期,我们很可能用的是一个根据经济扩张和萧条两个阶段的数据回归得到Beta,即0.7×0.5+1.5×0.5=1.1,进一步运用CAPM得到下一阶段资产**益率为3%+1.1(20%×0.5+5%×0.5-3%)=13.45%,比10.45%的预期高出了3%。 由于未将系统性风险随经济周期发生变化的因素考虑到模型的输入变量中,我们得到预测结果是不准确的。 在量化投资风生水起的大环境下,广大果仁同学们要时刻保持清晰的思路和清醒的头脑,学会甄别量化投资中的伪科学。要知道,量化不等于科学,有的“量化外衣”下只不过是用一些数学和统计工具粉饰的滥竽充数者。请记住,量化是我们的研究手段,而非目的,我们追求的是科学的投资方式。一种投资策略,只要遵循科学的研究方法,不论运用定性分析还是定量分析,都是科学投资。 免责申明:本文内容(包括但不限于文字,图片等内容)来自网络或者宽客之家社区用户发布,仅代表作者本人观点,与本网站无关。本网站不对所包含内容的准确性、可靠性或完整性**任何明示或暗示的保证,并读者理性阅读,并自行承担全部责任!如内容不慎侵犯了您的权益,请联系告知,核实情况后我们将尽快更正或删除处理! |